
By Paul J. Bruemmer
 |
"Website? What's a website? That is what I was hearing 11 years ago when prospecting for search engine optimization (SEO) clients. Now, thousands of new websites are created every day. Whereas the evolution of the website has been an incredible journey with many changes over the years, there is one common denominator that has not changed much at all - what search engines see when crawling a site. Search engines have certainly improved the delivery of relevant data to our search queries and vastly increased the size of their databases. But what they see today is pretty much the same as in 1995 - HTML. However, not all websites are alike. |
Under the Hood
To give us a better understanding, let's look at two prominent and competing websites that show measurable differences in what a search engine finds and subsequently indexes. This is what you and I will see when we go to The Wall Street Journal.
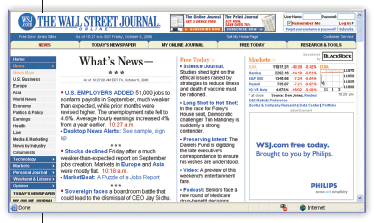
Below is the same URL as seen by a search engine. This time the total count is 140 words, and none of the words match those from the browser screen shot.

Best practice is to provide unique Title and Description Meta Tags for each individual page within a website, using keywords that describe the page content. This helps the search engine determine exactly what the site is all about (e.g., Mustang horse versus Mustang car).
Now, let's take a look at The New York Times website.
When looking at these two websites from a browser they appear to be very similar - a header, sidebar, content, links and ads. However, when you look at them from a search engine point of view, the numbers speak for themselves. There is a big difference between what Google sees at The Wall Street Journal and The New York Times.
The New York Times website in Google
- 2,960,000 pages indexed
- 196,000 link backs (inbound links) to home page
- No redirect of any type
The Wall Street Journalwebsite in Google
- 394 pages indexed
- 23,000 link backs (inbound links) to home page
- 302 redirect to online.wsj.com
The New York Times has nearly 3 million more Web pages indexed and 170,000 more inbound links to their home page compared to The Wall Street Journal. The Wall Street Journal also has that nasty 302 redirect code.
Given these differences, I can assure you WSJ.com is at a serious disadvantage with respect to its organic keyword rankings and its daily, weekly, monthly and annual traffic volumes.
Is there something you can do to make your website more like The New York Times and less like The Wall Street Journal? You bet. All it takes is some advanced planning and adequate consideration to the way search robots interact with your site.
Planning Ahead for Organic Rankings
First, let's preface the planning exercise with a quick review of user experience.
User experience involves looking at all aspects of a user's encounter with a product or service, ensuring everything is in harmony.
Disciplines under the umbrella of user experience include information architecture, interaction design, user interface design, communication or graphic design, and usability engineering.
Planning a website for a good user experience and maximum search engine utility requires a comprehensive knowledge of how search engines work. The following information provides a basic outline of search engine issues to consider during your website planning process. While this list is not exhaustive, it will get you started with your basic search engine considerations.
Server
Your first consideration is the server, as it is the first point of contact a search engine will have with your website. There are essentially two server choices, dedicated or virtual hosted.
A dedicated server is the better choice, because it allows for much more flexibility and provides the ability to keep your IP address clean - this means a clear history devoid of spamming.
It's also important to have a dedicated IP address, rather than a shared IP address. When using a dedicated address, a search engine will have a unique thumbprint for your website. A shared IP acts as an intermediary agent on behalf of its customers - in which case the originating IP addresses might be hidden from the server.
Also, be sure that your reverse DNS entry is configured properly. This will help search engines move through their checklist quickly - as will placing a robot.txt file in your root directory and ensuring that alias and/or multiple URLs are managed properly.
Finally, non-www domain names should be 301 redirected to your www domain name to avoid search engine canonical issues.
All of these steps will make sure that when a search engine robot arrives at your site, it will have a red carpet experience.
Site Architecture
The layout and structure provided for the information architecture of your website should represent the flow of wellorganized
data throughout the site. Remember, search engines are robots, not human beings. Their speed of gathering data requires that you provide them with a clear path for crawling, digesting and comprehending your entire website in a very thorough and reliable manner.
Best practice recommends a technician with a complete understanding of search engines to be assigned to the sitemap and wire frames development process.
However, before sitemap and wire frame development, start by conducting keyword research, using AdWords or similar tools. Keyword research is the cornerstone for all search engine work and accomplishing your online business goals.
After keyword research and content creation, do a thorough analysis of your content and subject matter before proceeding with your sitemap and wire frames development.
If this is a redesign project, you must complete a diagnostic audit prior to developing your sitemap and wire frames. The audit will point out existing technical and editorial factors hindering top organic keyword rankings. The audit will also identify any top organic keyword rankings you won't want to lose during the redesign or site move due to changes in architecture, such as directory and page naming conventions.
Here is an outline for your initial steps:
Keyword research
- Include research on your top five competitors
Diagnostic audit
- Identify technical and editorial roadblocks.
- Identify existing top rankings, when applicable.
- Plan ahead by analyzing content and subject matter.
Sitemap and wire frames
- Determine directory and page naming conventions.
- Use your keywords
- Minimize duplicate pages
- Consider internal link structure protocol for search engines.
- Link up to top of directory structure
- Use keywords in your anchor text
- If possible, provide a sitemap Web page linking to all pages in your website.
- Provide a Privacy Statement or Policy page.
Page Construction
Another important consideration during the planning stage is the characteristics of your page construction. Although search engines love simple HTML code, not everyone can deliver simple HTML for a variety of reasons - including shopping carts and content management systems.
However, there is a minimum standard you must consider if you expect a search engine to rank your site as a subject matter expert in the top organic shelf space. Understanding basic robot protocol will help with your planning.
Meta Tags
The Title and Description Meta Tags are very important to a search engine. It is necessary to include these tags within each of your Web pages to achieve high rankings. The tags must be unique to each page and include a primary keyword that is also included within the content of the page.
Alt Tags
ALT Tags are brief descriptions, including keywords that describe a photo or image on your page. These are very helpful to robots when determining the overall relevance of your site.
Heading Tags
Heading Tags further inform the search engine robot of the context or meaning of the words on the page. It's important to always use a keyword in your Heading Tags while avoiding using more than three or four words.
Text on the Page
It is mandatory that text on the page includes a primary keyword - the same keyword located in the title and description Meta Tags. It is helpful to also include four or five supporting keywords.
Text navigation
It is always useful to provide alternatives for a robot to crawl your website. If your navigation bar is not made up of text links, it will be helpful to include a group of navigation text links at the bottom of all pages.
Providing a sitemap Web page with text links to all of the pages in your website allows for easy location and indexing by search spiders. However, avoid more than 50 text links on a page and break up your sitemap Web page, if necessary, into multiple sitemap pages.
JavaScript and Style sheets
Externalize JavaScript and style sheets. The reason for this is to position the body content of any given Web page as far up within the page code as possible. Studies show that the higher up the body content is on the page, the more relevant it is to the search engine.
External Influences
There are other, external influences that should be taken into consideration when planning for organic rankings.
During a Web crawl performed by a robot like Google, many duplicate and near-duplicate Web pages and documents are encountered. One study suggests more than 30 percent are duplicates. Multiple URLs for the same page, the same website hosted on multiple host names and Web spammers cause robots like Google to discard some and use what is considered unique content.
Robots want to avoid storing near-duplicate copies, and returning near-duplicate Web pages in their results. To improve rankings, ensure that your Web pages are not considered duplicates by the robots. There are several online tools available to check for duplicate content on your site.
Finally, perform a close examination of your inbound links. Although link popularity is a very important part of the ranking algorithm, it can be thought of as "relevancy validation. Given that each link has its own value, it is important to understand their attributes, (i.e. quality vs. quantity). Good links come from sites that are credible and trusted subject-matter experts.
For a complete description of these types of links and how to get them, consider reading this information authored by Todd Malicoat at https://www.stuntdubl.com/2006/08/21/linktypes/.
Search engines are a major part of the Internet experience for millions of users every day. It makes good business sense to take the necessary steps to be part of a positive experience.
Therefore, it is wise to plan ahead by giving adequate consideration to the way search engine robots will interact with your website. Site design, optimization and implementation require teamwork and many sets of considerations, but the results will be well worth the effort. ■
Paul J. Bruemmer is the Director Search Marketing at Red Door Interactive, www.reddoor.biz